Python爬蟲數據建模應用,怎麼這麼有趣!
爬蟲技術在數據世界中的奇妙冒險
在這個數據驅動的時代,數據就是力量,而如何有效地收集和分析這些數據是每個數據科學家都面臨的挑戰。Python爬蟲技術扮演著一個非常重要的角色,尤其在抓取手機APP的數據時,這一技術更是無可或缺。本文將深入探討如何利用Python編寫爬蟲程序來抓取和解析手機APP數據,並結合數據建模技術來分析這些數據。
為什麼選擇Python作為數據抓取工具?
Python以其簡潔的語法和豐富的庫而聞名,這使它成為數據科學家的寵兒。特別是在爬蟲技術上,Python提供了如Scrapy、BeautifulSoup和Requests這樣強大的工具,使得數據抓取變得輕而易舉。同時,Python在數據分析和建模方面也有非常強大的支持,比如Pandas、Numpy、Matplotlib等等。
數據結構與算法的應用: 如何提升數據處理效率?
在數據建模中,合適的數據結構和算法可以極大地提高處理效率。排序算法和搜索算法是其中的兩大關鍵角色。
- 排序算法:排序算法如快速排序、合併排序等可以對數據進行排序,提高後續查詢的效率。
- 搜索算法:利用二分搜索等高效搜索算法,可以在大量數據中迅速找到目標元素。
怎樣選擇合適的數據結構?
選擇合適的數據結構是數據建模的基石。比如:
- 哈希表:適合用於快速查找和插入的操作。
- 鏈結串列:適合於需要頻繁插入和刪除的場景。
- 樹結構:如二叉樹、B樹,適合用於需要快速搜索的應用場景。
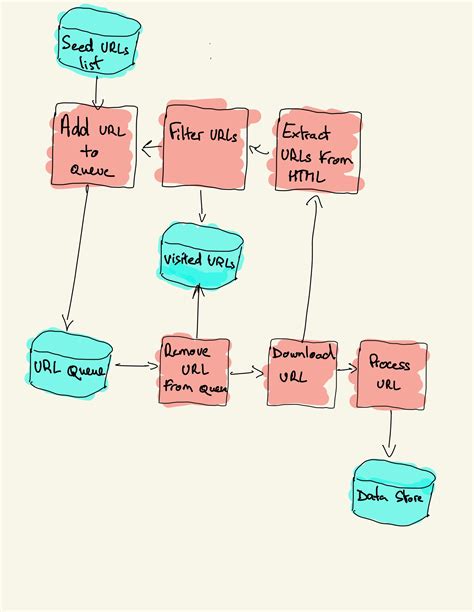
Python爬蟲技術: 從數據收集到清洗的步驟
爬蟲技術的應用分為數個步驟,從數據的收集到清洗,再到最終的應用,每一步都需要精心設計。
開始你的爬蟲冒險
- 數據收集:使用
Requests或Scrapy等工具抓取網頁數據。 - 數據解析:利用
BeautifulSoup或lxml解析HTML結構,提取所需數據。 - 數據清洗:清理重複數據和噪聲,確保數據質量。
特徵工程有多重要?
一旦數據收集完畢,接下來就是對數據進行探索和特徵工程。這是數據建模中至關重要的一環,因為特徵的選擇和處理將直接影響模型的效果。
模型選擇與訓練: 讓數據發揮最大效益
選擇合適的模型進行訓練是數據建模的核心,這一步決定了能否從數據中提取出有價值的洞見。
哪些模型技術最受歡迎?
- 回歸分析:用於預測和預測模型。
- 聚類分析:用於數據分群。
- 時間序列分析:適合時間相關數據的分析。
利用Python進行模型訓練
Python的Scikit-learn庫提供了大量的機器學習算法,這些算法可以方便地用於模型選擇和訓練。通過調參和交叉驗證,確保模型的穩定性和準確性。
數據建模的評估與優化: 如何達到另人驚嘆的效果?
在模型訓練完成後,對模型進行評估和優化是不可或缺的步驟。這樣才能確保模型在實際應用中不會失控。
如何評估模型的表現?
- 使用混淆矩陣、準確率、精確率等指標來評估模型表現。
- 通過A/B測試來驗證模型的實際效果。
模型優化的技巧
- 超參數調整:使用網格搜尋或隨機搜尋來找到最佳超參數組合。
- 特徵選擇:去除對模型貢獻不大的特徵,提升模型效率。
常見問題
為什麼Python是數據分析的最佳選擇?
Python不僅語法簡單,還擁有豐富的數據分析庫,如Pandas、Numpy,這些工具大大提升了數據處理效率。
爬蟲技術是否會侵犯隱私?
只要遵循法律規範和網站的robots.txt協議,爬蟲技術本身並不侵犯隱私。
如何保證數據模型的準確性?
通過交叉驗證和持續優化來確保模型的準確性和穩定性。
可以自學Python爬蟲技術嗎?
完全可以!網上有大量的教學資源和開源項目,可以幫助你快速上手。
哪些工具可以幫助加速Python數據分析?
NumPy、Pandas、Matplotlib等庫可以極大地提高數據分析的效率。
結論
從Python爬蟲技術到數據建模,這一連串的技術不僅讓數據科學家能夠收集到寶貴的數據,還能通過模型分析得到有價值的洞見。隨著技術的發展,這些技術將在未來的數據科學中扮演更重要的角色。