如何利用網頁爬蟲資料儲存教學來獲取你想要的資訊?
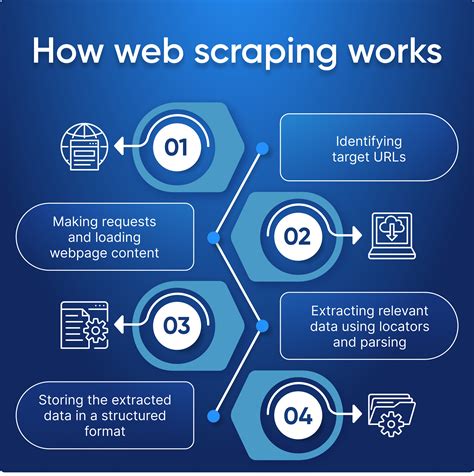
為什麼要學習網頁爬蟲?
網頁爬蟲技術已逐漸成為數位時代的必備技能之一。無論你是想追蹤股票市場的最新動態,還是想從眾多網站中提取所需的數據,網頁爬蟲都是一個強大的工具。尤其在商業分析、學術研究、甚至是個人興趣上,網頁爬蟲能讓你如虎添翼!
什麼是網頁爬蟲?
網頁爬蟲,顧名思義,就是一種自動化的程式,用來在網頁上抓取資料。說白了,這就像派出一隻小機器人,代替你瀏覽網頁,並把你需要的資訊帶回來。這些資訊通常存在於HTML文件中,而我們的目標就是從中提取有用的數據。
工具選擇:Python、Requests 和 BeautifulSoup4
Python:程式設計的瑞士刀
Python因其簡潔的語法和強大的函式庫支援,成為許多爬蟲開發者的首選。Python中的requests庫和BeautifulSoup4庫,更是如魚得水般在網頁爬蟲領域大顯身手。
Requests:HTTP請求的神器
requests庫讓HTTP請求變得簡單如呼吸。它能夠輕鬆發送GET和POST請求,這在爬蟲中尤為重要,因為我們需要通過GET請求獲取網頁內容。
BeautifulSoup4:HTML解析的利器
BeautifulSoup4則是在解析和處理HTML文件時的最佳助手。它能夠輕鬆地從HTML中提取各種元素,如標籤、屬性和文字內容。
Yahoo奇摩股市案例:實戰演練
接下來,我們將以Yahoo奇摩股市為例,示範如何利用Python網頁爬蟲取得股票資料,並將其存入MySQL資料庫中。這不僅有助於後續的數據分析,還能讓你建立自己的數據庫系統。
第一步:了解目標網站結構
了解網站的HTML結構是成功爬取數據的關鍵。打開Yahoo奇摩股市的網頁,使用瀏覽器的開發者工具檢查網頁元素,找出你需要的數據所在的HTML標籤和屬性。
第二步:發送HTTP請求
利用requests庫發送GET請求,獲取網頁的HTML內容:
|
|
第三步:解析HTML內容
使用BeautifulSoup4解析HTML,提取所需的股票數據:
|
|
第四步:將數據存入MySQL
獲取數據後,將其存入MySQL資料庫中。首先,確保你已安裝MySQL和相關的Python MySQL連接器:
|
|
問題排解:常見挑戰與解決方案
如何處理需要點擊才能顯示的內容?
有些網頁內容需要點擊才能顯示,這時我們可以使用Selenium,它能夠模擬用戶行為,點擊按鈕或鏈接以載入動態內容。
如何避免被網站封鎖?
為了避免被網站識別為爬蟲並封鎖,我們可以在requests中加入headers模擬瀏覽器請求,或使用代理IP來隱藏真實IP地址。
如何處理JavaScript生成的內容?
對於JavaScript生成的動態內容,我們可以使用網頁爬蟲庫Scrapy搭配Selenium來解決。
Python爬蟲是否合法?
在進行網頁爬蟲前,務必閱讀並遵循網站的robots.txt文件,以確保不違反網站的使用條款。
如何提高爬取速度?
可以使用多線程或異步編程技術來提高爬取速度,然而必須注意不給目標網站帶來過大負擔。
如何處理異常狀況?
在發送請求時,應加上異常處理機制,如try-except塊,以應對網絡波動或網站變動帶來的錯誤。
結論
網頁爬蟲技術不僅是數據科學家的強力工具,也是每一位渴望從網路中挖掘資訊的人的福音。只要掌握了Python及其相關庫如requests和BeautifulSoup4,你便能輕鬆獲取並處理網頁上的數據。